Um Untersuchungsergebnisse in die Kartei eines Patienten zu importieren, können unter Einstellungen → Datei-Import Dateilauscher konfiguriert werden. Dabei wird zwischen zwei Lauschertypen unterschieden: GDT und Andere
Wird eine Datei von einem GDT-Lauscher eingelesen, werden Untersuchungsergebnisse entsprechend der GDT-Feldziffern in einen Karteieintrag eingelesen. Dabei lassen sich normale Karteieinträge und Custom-Karteieinträge erzeugen. An normale Karteieinträge wird die eingelesene GDT-Datei als Anhang hinzugefügt.
Wird eine Datei von einem anderen Dateilauscher eingelesen, wird ein Karteieintrag des ausgewählten Typs erstellt und die Datei als Anhang hinzugefügt. Es werden dabei keine Informationen aus dem Inhalt der Datei ausgelesen.
Konfiguration eines Dateilauschers
In der Seitenleiste lässt sich über Einstellungen → Datei-Import ein neuer Dateilauscher anlegen.

Neuen Dateilauscher anlegen
Durch einen Klick auf "+" in der Seitenleiste öffnet sich ein Dialog, in dem der Name des neuen Lauschers und der Lauschertyp ausgewählt werden müssen.

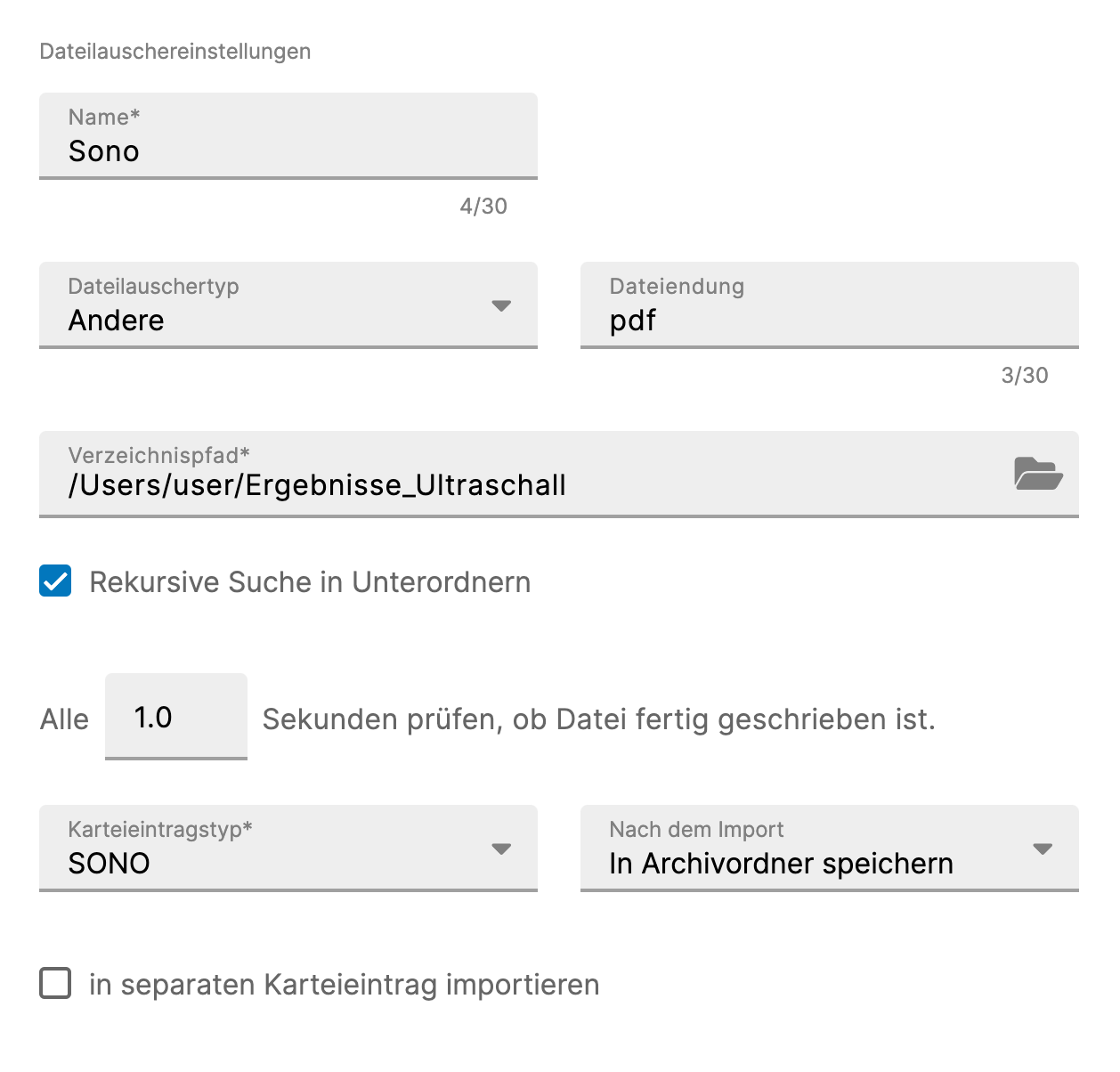
Allgemeine Lauschereinstellungen
Bei der Erstellung eines Dateilauschers müssen pflichtmäßig folgende Eingaben getätigt werden:
- Name – Name des Dateilauschers, der in der Seitenleiste angezeigt wird
- Verzeichnispfad – Austauschordner, in welchem auf Dateien gelauscht wird
- Rekursive Suche in Unterordnern – Es wird in allen Unterordnern des angegebenen Verzeichnispfades auf Dateien gelauscht. Davon ausgenommen ist der Archiv-Ordner mit Unterordnern (falls vorhanden)
- Aktualisierungsintervall – Zeitraum, der seit der letzten Änderung der Datei vergangen sein muss, bevor die Datei eingelesen wird. Dies dient dazu abzuwarten, falls eine Datei noch geschrieben wird
- Verfahren mit Dateien nach erfolgreichem Import – Dateien löschen oder in Archivordner speichern. Bei der Option "in Archivordner speichern" wird automatisch eine Archivstruktur im belauschten Verzeichnis angelegt, falls nicht vorhanden: "Archiv" → Jahr → Monat → Tag
- Karteieintragstyp (Ausnahme siehe Typ automatisch ermitteln, nicht für LDT-Lauscher) – Beim Einlesen einer Datei wird ein neuer Karteieintrag des entsprechenden Typs angelegt
- in separaten Karteieintarg importieren (nicht für LDT-Lauscher) – Ist die Option ausgewählt, wird für jede vom Lauscher importierte Datei ein eigener Karteieintrag angelegt. Ist sie nicht ausgewählt, werden Dateien an vorhandene Karteieinträge des gleichen Karteieintragstypen angehängt, falls für den Patienten bereits ein Karteieintrag am gleichen Tag vorhanden ist. Die Option kann nur gewählt werden, wenn es sich bei dem Karteieintrag nicht um einen Custom-Karteieintrag handelt, da diese nicht sinnvoll erweitert werden können.
Nach erfolgreichem Datei-Import, lässt sich
- automatisch eine Aufgabe anlegen – Im tomedo macOS Client werden die ausgewählten Nutzer*innen auf die neue Aufgabe hingewiesen. Die Aufgabenbeschreibung ist der Titel der Aufgabe. Weiterhin kann die Prioriät und die Fälligkeit (in Stunden nach dem Datei-Import) festgelegt werden. Die Verantwortlichen können über das Editieren-Symbol angepasst werden. Dann öffnet sich ein Dialog, in dem Nutzer oder Nutzergruppen ausgewählt werden können. Schließlich lässt sich noch festlegen ob die Augabe von allen Verantwortlichen erfüllt werden muss, oder nur von Einem.
Dateifilter und Patient:innenzuordnung
Der Abschnitt enthält folgende Konfigurationsmöglichkeiten, die zusätzlich je nach Lauschertyp mehr oder weniger sinnvoll eingesetzt werden können:
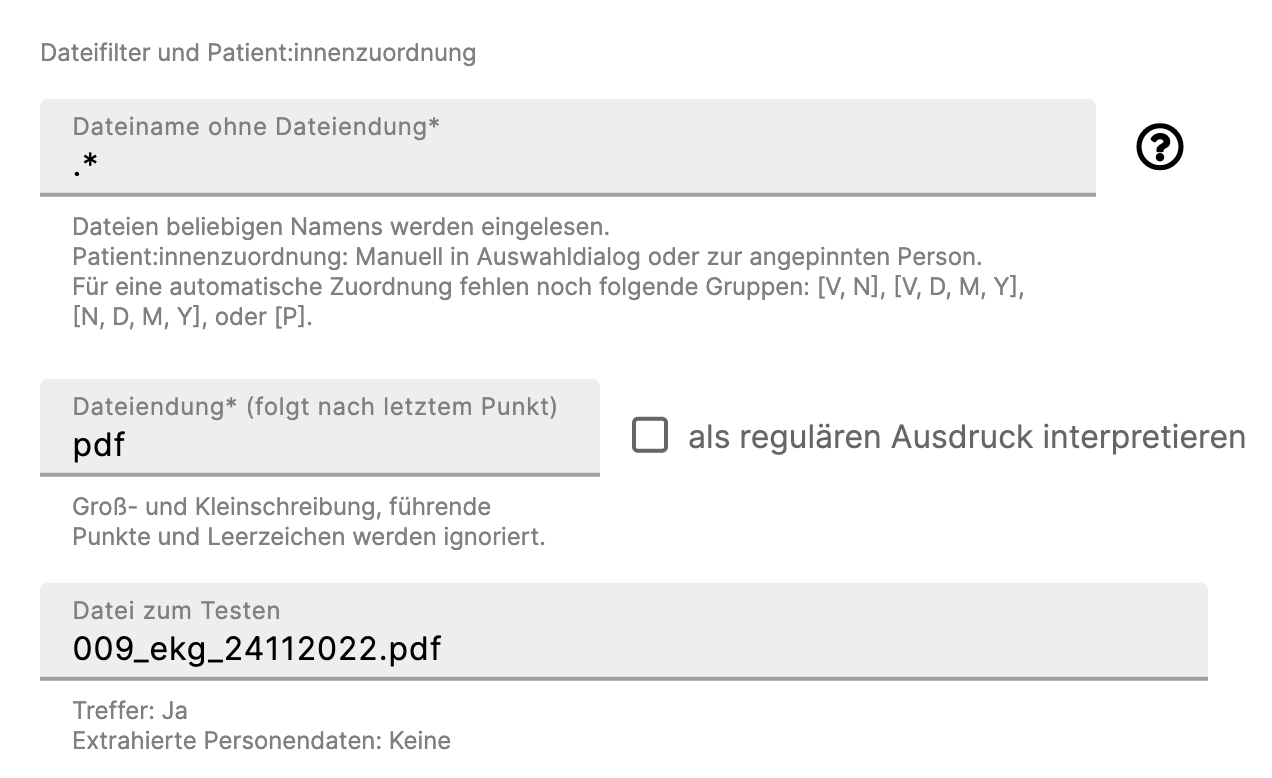
- Dateiname ohne Dateiendung – Hier können Nutzer:innen einen regulären Ausdruck für den Dateinamen bestimmen.
Wichtig: Liest LINK eine Datei ein, dann wird der Teil vor dem letzten Punkt als Dateiname interpretiert!
Beispiel: Das System liest die Datei "130822_max_mustermann.sono.gdt" ein. → Dateiname: "130822_max_mustermann.sono", Dateiendung: "gdt". - Dateiendung – Hier kann die Dateiendung spezifiziert werden. Dabei spielt Groß- und Kleinschreibung keine Rolle. Ebenso werden Leerzeichen und führende Punkte (sofern die Eingabe nicht als regulärer Ausdruck interpretiert werden soll!) und ignoriert.
Mehrere erlaubte Endungen können durch Kommas getrennt werden. Für mehr Flexibilität kann man den Ausdruck auch als regulären Ausdruck interpretieren lassen. - Datei zum Testen – Um zu testen, ob die beiden obigen Konfigurationen den Erwartungen entsprechen, können Nutzer:innen hier einen besipielhaften Dateinamen angeben.
- Dateiinhalts-Filter – Wenn der Dateiinhalts-Filter gesetzt ist, wird der Datei-Inhalt vor dem Datei-Import gepürft. Nur Dateien, deren Inhalt einen Treffer für diesen regulären Ausdruck aufweisen, werden importiert.
Sofern mehrere Lauscher auf denselben Pfad (bzw. untergeordnete Pfade) lauschen, müssen die regulären Ausdrücke dann für diese Lauscher auch unterschiedlich bzw. eindeutig sein. Falls dies nicht so ist, werden die Eingaben der Nutzer:innen nicht als gültig akzeptiert.
Lauschertyp "GDT"
Für diesen Lauschertyp beziehen sich die Angaben lediglich auf die Filterung der in Frage kommenden Dateien. Eine Patient:innenzuordnung kann nicht über den Dateinamen erfolgen, sondern über die in der Datei enthaltenen Informationen, welche daraus extrahiert werden. Im folgenden Beispiel sollen Dateien mit einer (vom Untersuchungsgerät) dreistelligen hochzählenden Dateiendung eingelesen werden, was nur möglich ist, wenn die angegebene Dateiendung als regulärer Ausdruck interpretiert wird.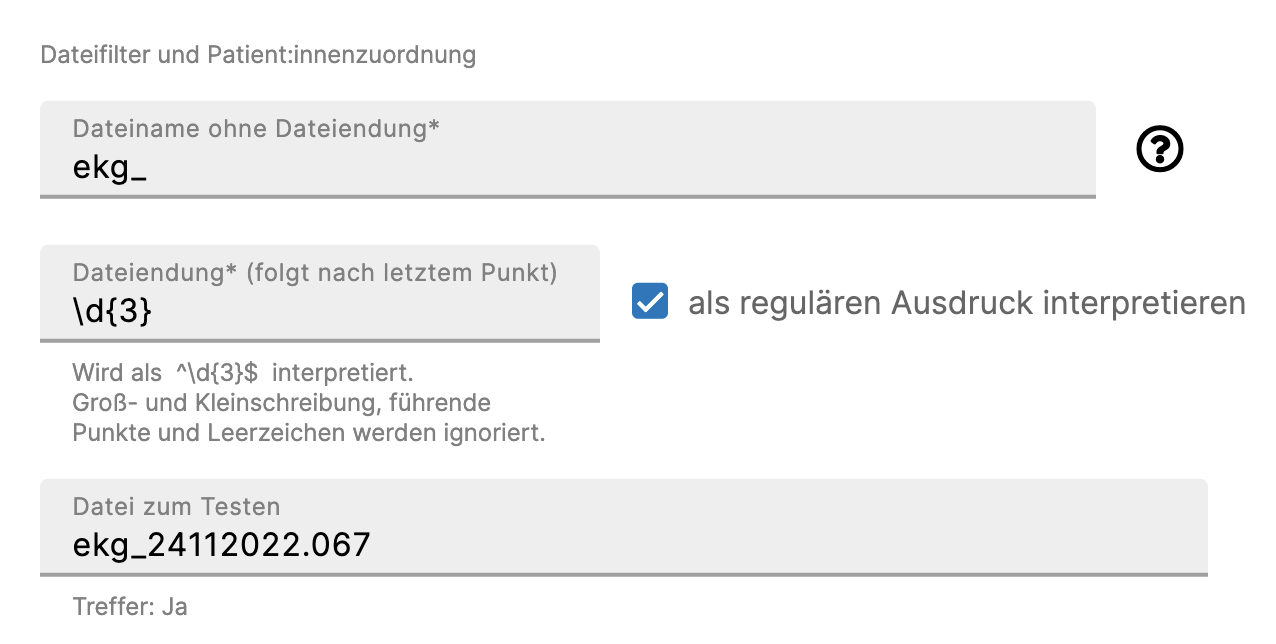
Lauschertyp "LDT"
Für diesen Lauschertyp beziehen sich die Angaben ebenfalls nur auf die Filterung der in Frage kommenden Dateien. Eine Patient:innenzuordnung kann nicht über den Dateinamen erfolgen. Diese führt der macOS Client nach dem Import eigenständig anhand der in der Datei vorhandenen Informationen durch.
Alle importierten Dateien werden an den Server gestreamt und dort entweder eingelesen oder abgelehnt, siehe Labor.
Im folgenden Beispiel sollen alle Dateien beliebigen Namens eingelesen werden, wobei drei verschiedene Dateiendungen erlaubt sind: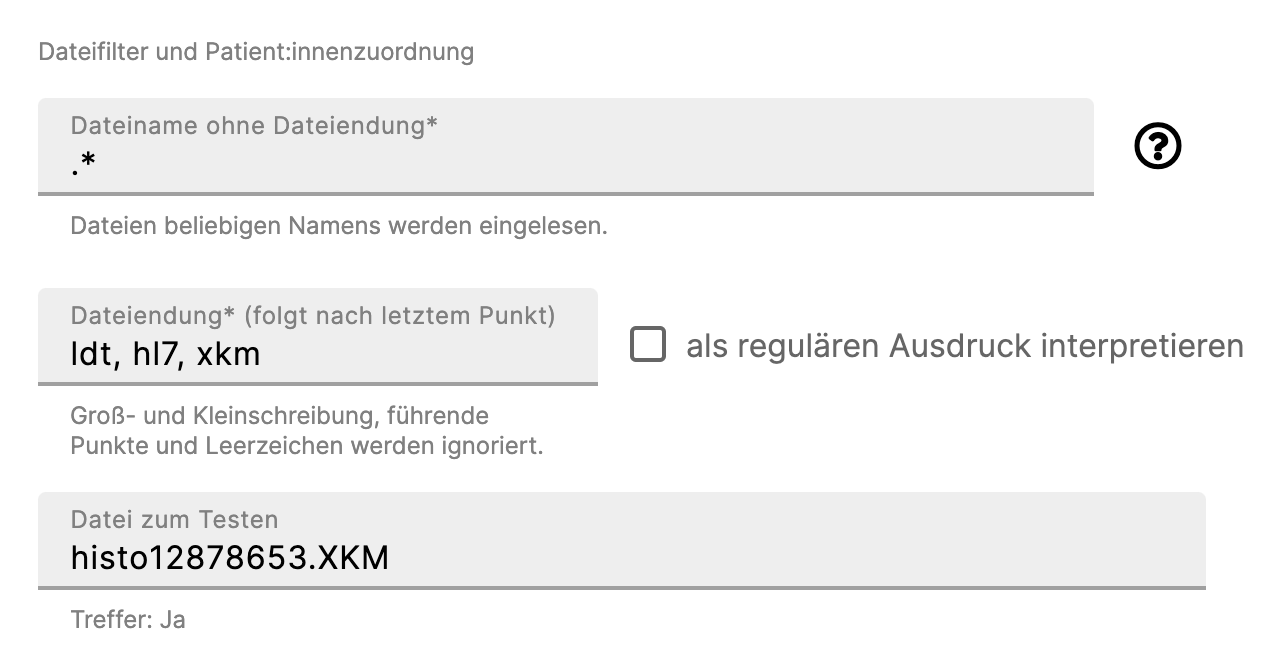
Lauschertyp "Andere"
- Falls der Dateiname der zu importierenden Datei Informationen über den Patienten bzw. die Patientin enthält, kann über einen regulären Ausdruck angegeben werden, an welcher Stelle des Dateinamens sich welche Patient*inneninformation befindet. Sollte unter dieser Einstellung die automatische Zuordnung trotzdem fehlschlagen oder nicht eindeutig sein, öffnet sich wieder der Dialog zur manuellen Dateizuordnung.
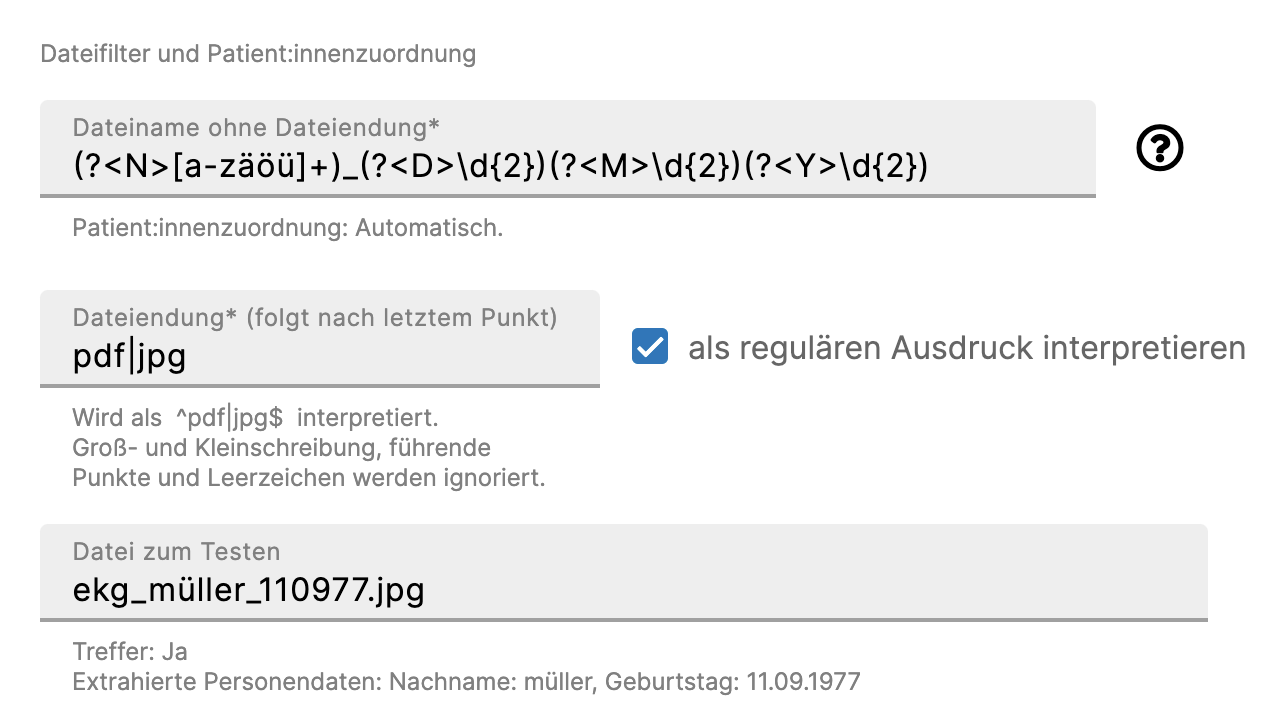
In tomedo.LINK ist eine Menge von Gruppennamen hinterlegt, die innerhalb eines regulären Ausdrucks mittels (?<gruppenname>ausdruck) verwendet werden können. - Beispiel für eine automatische Zuordnung:
Der Dateiname lautet ekg_müller_110977.jpg. Man weiß bei Einrichtung des Dateilauschers, dass das entsprechende Gerät immer diesem Muster folgt (die Zahlen am Anfang des Dateinamens sollen nichts mit der untersuchten Person zu tun haben und stellen hier lediglich eine hochzählende Nummer dar). Dann kann man folgende Einstellung verwenden:
- Falls bekannt ist, dass die Dateinamen der zu importierenden Dateien keine Informationen über Patient*innen beinhalten und damit eine automatische Zuordnung nicht möglich ist, kann es sinnvoll sein, direkt nach dem Erlauschen der Datei einen Dialog öffnen zu lassen, in welchem Nutzer*innen zur manuellen Dateizuordnung aufgefordert werden. Allerdings muss in jedem Fall ein regulärer Ausdruck definiert werden, um die für diesen Lauscher infrage kommenden Dateien zu filtern. Eine manuelle Zuordnung erreicht man dadurch dass im regulären Ausdruck auf die Angaben von Gruppennamen verzichtet wird. Um Dateien beliebigen Names für den Lauscher zu qualifizieren, genügt der reguläre Ausdruck ".*".

Weitere Optionen eines Lauschers vom Typ 'GDT'
Für GDT-Lauscher gibt es weitere Optionen, die sich auf die Verarbeitung des Inhaltes der eingelesenen GDT-Datei beziehen:
- Zeichensatz (Dekodierung) – Zum Öffnen und Auslesen der GDT-Datei wird ein Zeichensatz benötigt. Im Dropdown kann aus den folgenden Zeichensätzen gewählt werden:
- UTF-8
- IsoLatin-1
- IsoLatin-2
- Windows-CP-1250
- Windows-CP-1252
- CP-437
- Darüber hinaus gibt es zwei spezielle Auswahlmöglichkeiten:
- Automatisch setzen: Zum Öffnen einer Datei testet der Lauscher die obenstehenden Zeichensätze ab. Der erste Zeichensatz mit dem sich die Datei öffnen lässt wird daraufhin für diesen Lauscher gesetzt und fortan für alle folgenden Importvorgänge verwendet.
- Betriebssystemspezifisch: Der Lauscher verwendet zum Öffnen der Datei den aktuellen Zeichensatz, den das Betriebssystem verwendet.

- Typ automatisch ermitteln – Ist in der GDT-Datei die Feldziffer 8402 (Untersuchungskennung) gegeben und stimmt der Inhalt mit dem Kürzel eines Karteieintragstypen überein, wird die Datei in einen Karteieintrag des entsprechenden Typs importiert. Sollte beim Import einer Datei kein passender Typ gefunden werden, wird die Datei nicht importiert. Ist diese Option gewählt, können Dateien nicht in den gleichen Karteieintrag importiert werden (siehe in separaten Karteieintrag importieren), da beim Anlegen des Lauschers nicht feststeht, ob es sich bei dem ermittelten Karteieintragstyp um einen Custom-Karteieintrag handelt.
- Karteieintragstyp-Zuordnungen – Sollte der GDT-Inhalt des Karteieintragstyps einer Datei von der Abkürzung in tomedo abweichen, lassen sich die abweichenden Kürzel zu den tomedo Kürzeln zuordnen. Über "Karteieintragstyp-Zuordnungen bearbeiten" öffnet sich ein Dialog. Dort kann für einen Karteieintragstyp ein neues Kürzel vergeben werden. Steht dieses Kürzel dann in der Datei wird der Karteieintragstyp korrekt zugeordnet. Jedes Kürzel kann nur einmalig vergeben werden. Sollte dies in Zukunft zu Abweichungen führen wird der Lauscher invalide und Nutzer*innen werden darauf hingewiesen.
Die Zuordnungen gelten für alle Lauscher. Jedoch kann für jeden Lauscher entschieden werden, ob diese berücksichtigt werden sollen. Dies ist nur möglich wenn der Typ automatisch aus der GDT ermittelt wird. - Karteieintragsdatum aus GDT – Das Karteieintragsdatum wird aus den Feldern Untersuchungsdatum und -uhrzeit (6200 und 6201) bestimmt. Sollte aus diesen Feldern kein Datum herausgelesen werden können, wird stattdessen das aktuelle Datum mit Uhrzeit verwendet.
- Empfängerkennung ignorieren – Ist diese Option nicht aktiviert, werden nur Dateien, deren Empfängerkennung (Feldziffer 8315) tomedo oder edv enthält, eingelesen

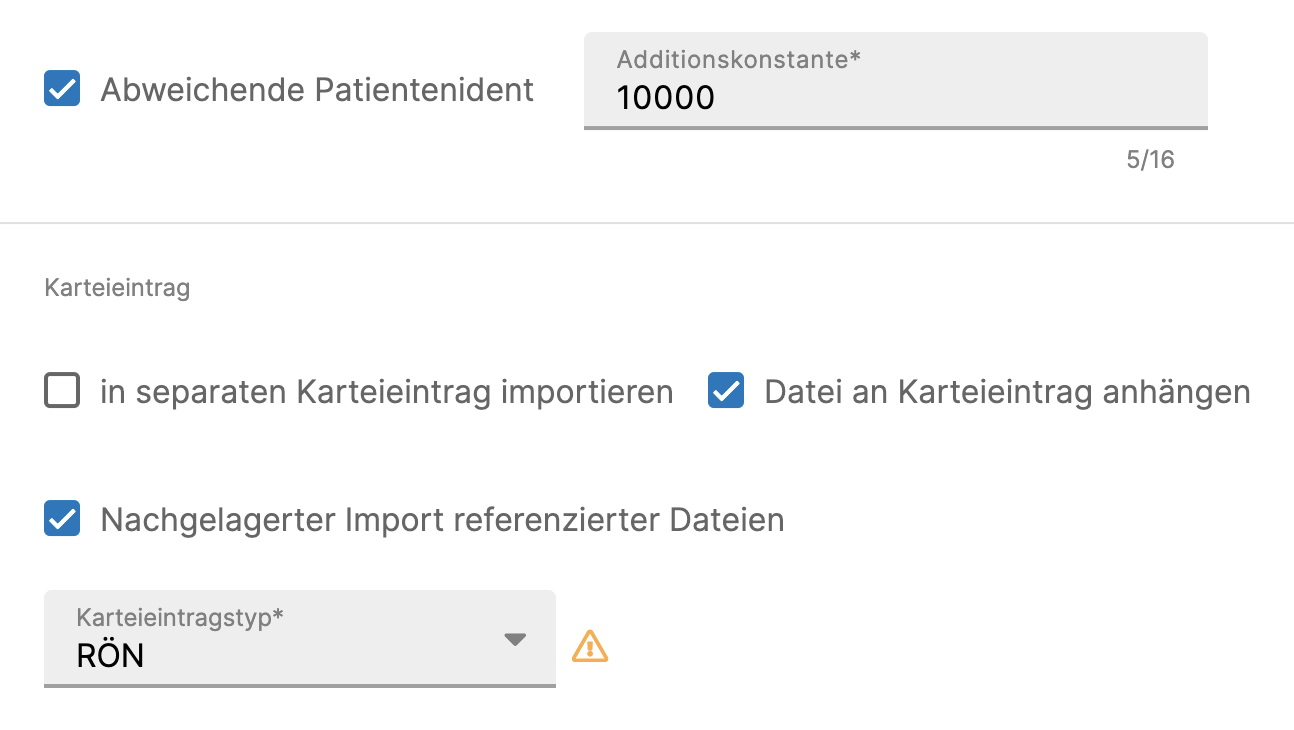
- Abweichende Patientenident – Sollte die Nummerierung der Patienten in der externen Gerätesoftware nicht mit der Nummerierung in tomedo übereinstimmen (z.B. aufgrund einer nachträglichen Datenmigration oder Praxiszusammenführung), kann eine Konstante angegeben werden, die beim Import auf die eingelesene Patient*innennummer addiert wird (oder bei negativen Zahlen subtrahiert wird).
- Datei an Karteieintrag anhängen – Ist der Haken gesetzt, so wird die eingelesene GDT-Datei an den erzeugten oder zu aktualisierenden Karteieintrag angehängt. Ist er nicht gesetzt, so wird lediglich der aus den GDT-Daten generierte Karteieintragstext in den Karteieintrag übernommen.
Hinweis: Wir die GDT-Datei in tomedo benötigt um Untersuchungen direkt aufrufen zu können, sollte diese Option nicht abgewählt werden! - Nachgelagerter Import referenzierter Dateien – Sollen weitere Dateien (PDFs, Bilder, etc.), deren Pfade in der GDT-Datei unter der Ziffer 6305 angegeben sind, zusätzlich importiert werden, so können Nutzer*innen diese Option verwenden. Die Option ist jedoch nur wählbar, sofern der gewählte Karteieintragstyp vom Standardmedientyp "Anhang" ist.
Umgekehrt kann kein Karteieintragstyp aus dem Dropdown gewählt werden, der nicht vom Typ "Anhang" ist, falls die Option des nachgelagerten Imports ausgewählt wurde.
Da für einen erfolgreichen Import zum Zeitpunkt des GDT-Imports auch bereits die referenzierten Dateien vorhanden und fertig geschrieben sein müssen, empfiehlt es sich ggf. den Wert X unter "Alle <X> Sekunden prüfen, ob Datei fertig geschrieben ist" leicht zu erhöhen.
- Karteieintragstext spezifizieren – Der Text, der in tomedo in den einzelnen Karteieinträgen steht, kann in einem gewissen Umfang formatiert werden.
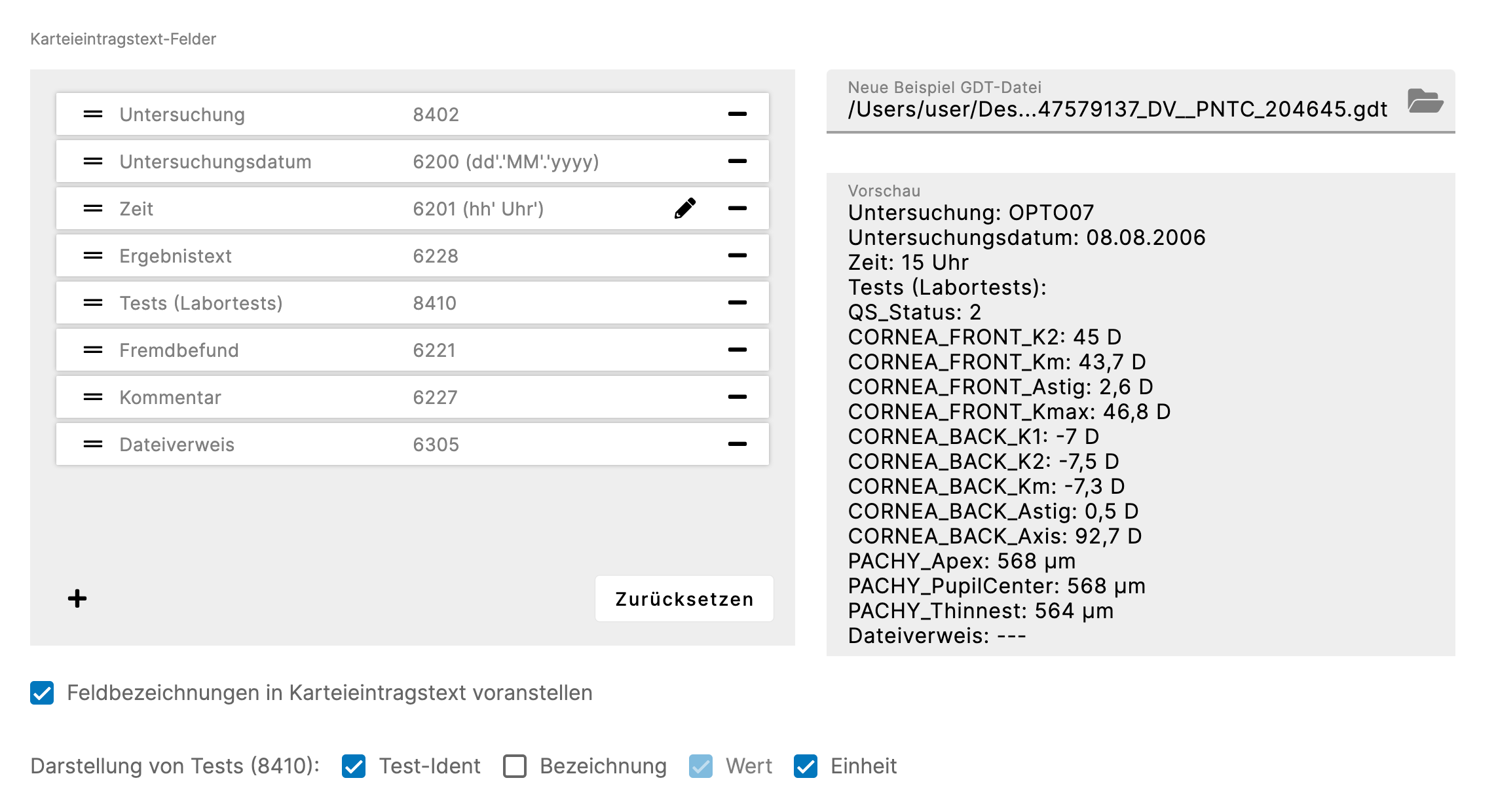
Hierzu wird eine Liste von Feldern angelegt, die bestimmt, welche Inhalte der GDT-Datei in den Karteieintragstext überommen werden.Um eine Vorschau zu erhalten, kann man eine beispielhafte GDT-Datei laden. Mit der vorhandenen Liste an Feldern wird dann automatisch ein Karteieintragstext generiert. Werden nun Änderungen an den Feldern (z.b. Umsortieren) vorgenommen, sind diese unmittelbar in der Vorschau zu sehen.
- Die Reihenfolge der Felder bestimmt die Reihenfolge der Inhalte (gelesen aus der GDT-Datei) im automatisch generierten Karteieintragstext. Per Drag- and Drop können die Felder umsortiert werden
- Sofern Testergebnisse vorhanden sind, werden diese alle dem Feld Tests (Labortests) zugeordnet
- Eine Zeile für einen Test besteht aus Test-Ident, Test-Bezeichnung, den Test-Wert (Messwert) sowie die Einheit des Test-Werts. Über Checkboxen kann bestimmt werden, welche Elemente davon im Karteieintragstext erscheinen sollen
- Inhalte/ Zeilen, die nicht in der GDT-Datei gefunden wurden, aber in der Liste stehen, werden für den Karteieintragstext ignoriert
- Fehlerhafte GDT-Inhalte werden als "—" in den Karteieintragstext geschrieben (das kann passieren, wenn bspw. eine Zeichenkette als Uhrzeit interpretiert werden soll, diese aber Buchstaben enthält)
- Die Feldbezeichnungen können über eine Checkbox im Karteieintragstext den Daten vorangestellt oder ignoriert werden
- Hinweis: Jede Feldziffer in der Liste kann maximal einmal vorkommen!
- Ist die Liste der Felder leer, wird zum Generieren des Karteieintragstextes ein Standardset an Feldern verwendet, welches sich auch über den Button Zurücksetzen wiederherstellen lässt.
- Möchte man Felder (Zeilen im Karteieintragstext) hinzufügen, so ist dies über das + Symbol möglich. Man kann hier entweder aus einer Liste von Standardfeldern wählen oder auch eigens definierte Felder erstellen:
- Standardfelder: Die auswählbaren Standardfelder sind mit festen Feldziffern belegt und richten sich nach dem GDT-Standard. Weicht die exportierte Datei eines Geräts bspw. von diesem Standard ab, so kann ein benutzerdefiniertes Feld garantieren, dass der Inhalt unter der entsprechenden Zeile trotzdem im Karteieintragstext erscheint:
- Eigenes Feld: Hierzu muss ein Feldname, eine Feldziffer, sowie ein Inhaltstyp gewählt werden. Mit der Auswahl einiger Inhaltstypen ist ein weiteres Eingabefeld für Formate vorhanden.




GDT-Importe in Custom-Karteieinträge und Laborwerte
Wurde als Karteieintragstyp eine Custom-Typ gewählt, so erscheint neben dem Dropdown eine Checkbox und ein Button, welche eine Zuordnung zu Custom-Karteieintragsvariablen erlauben:

- Berrücksichtigung der Variablenzuordnung:
- Definieren einer Variablenzuordnung (Button "Variablen-Zuordnungen bearbeiten")
- Für den ausgewählten Custom-Karteieintragstyp ist eine Liste der in tomedo verfügbaren Variablen (mit Typ) zu sehen. Sofern man "Typ automatisch ermitteln" verwendet, kann man im Zuordnungsdialog trotzdem für alle verfügbaren Custom-Karteieintragstypen Zuordnungen definieren und bearbeiten.
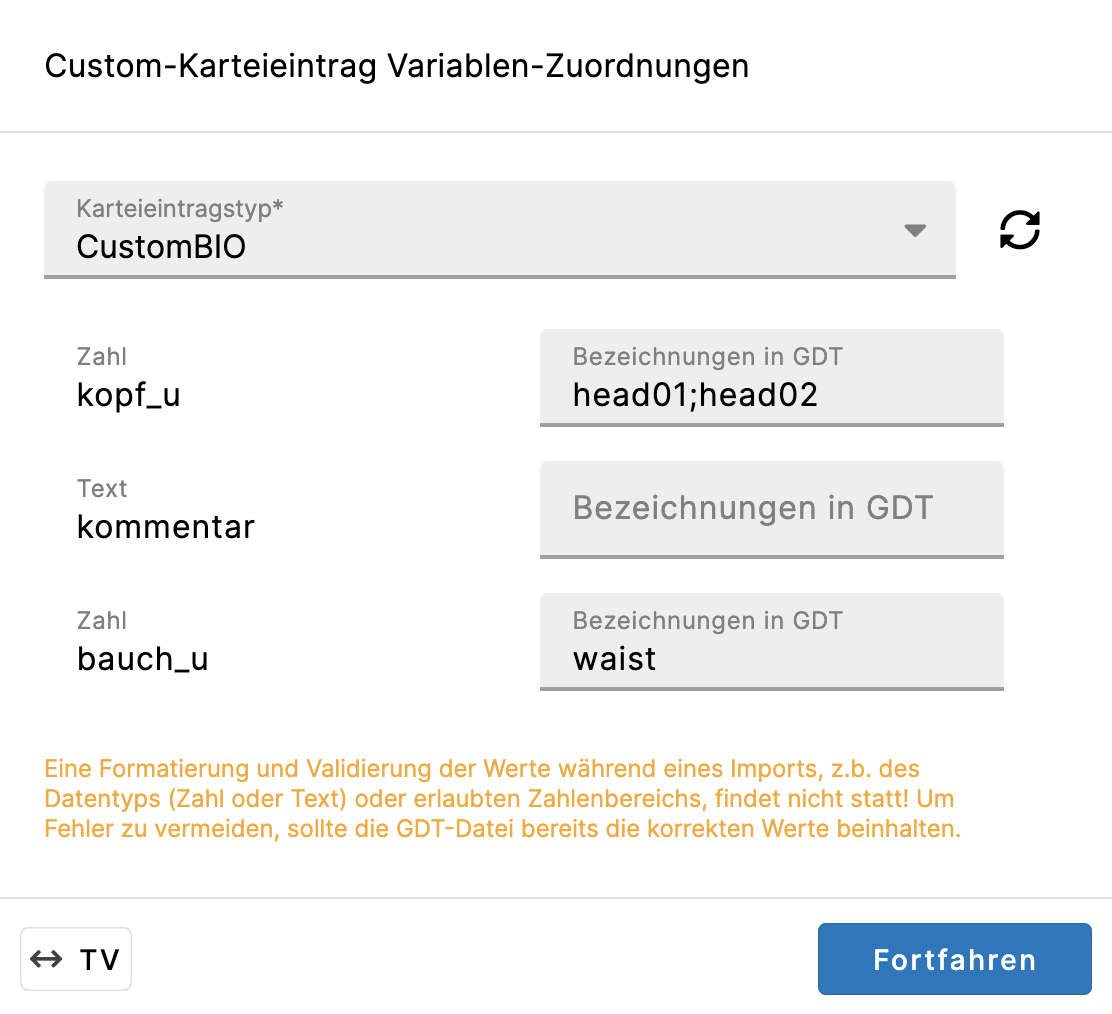
- Pro Variable steht ein Textfeld zur Verfügung, in welchem die entsprechenden Bezeichnungen hinterlegt werden können, wie sie in einer zu importierenden GDT-Datei hinter der Ziffer 8410 auftauchen würden.
- Für eine Variable können mehrere Bezeichnungen angegeben werden.
- Pro Custom-Karteieintragstyp darf eine Bezeichnung nur einmal vorkommen

- Sobald eine GDT-Datei importiert wird und die Checkbox "Testwerte in CKE-Variablen übertragen" aktiv ist, werden die Messdaten (Ziffer 8420) in diejenige Variable geschrieben, welche als Ersatzbezeichnung den Wert hinter der entsprechenden Testident der GDT-Datei (Ziffer 8410) haben.
- Definieren einer Variablenzuordnung (Button "Variablen-Zuordnungen bearbeiten")
- Ohne Berrücksichtigung der Variablenzuordnung:
Ist der gewählte Karteieintragstyp ein Custom-Karteieintragstyp und ist es gewünscht, dass Felder des Karteieintrags mit den Werten aus der GDT-Datei befüllt werden, so ist es notwendig, dass die Variablennamen im Custom-Karteieintragstyp mit den Feldziffern des entsprechenden Inhalts übereinstimmen. Soll bspw. ein Befund unter der Ziffer 6220 im Custom-Karteieintrag stehen, so muss die Variable im Custom-Karteieintragstyp ebenfalls 6220 heißen.- Labormesswerte aus einer GDT-Datei können in einen Custom-Karteieintrag geschrieben werden, falls die Variable den Namen 8410 hat
- Die GDT-Inhalte unter den Ziffern 8411 (Test-Name), 8420 (Test-Wert), 8421 (Einheit), 8417 (Werte einer Test-Reihe), 8480 (Testergebnis), sowie 8432 (Testdatum) und 8439 (Testzeit) können nicht einzeln in einen Custom-Karteieintrag geschrieben werden, da diese Ziffern innerhalb einer GDT-Datei beliebig oft auftreten können. Diese Ziffern sind auch nicht unter dem Abschnitt Karteientragstext-Felder für ein custom GDT-Feld wählbar.
Es können lediglich alle (Labor-)Tests mit den jeweiligen Unterwerten zusammen unter der Ziffer 8410 importiert werden.
- Angenommen man möchte Untersuchungsergebnisse aus einem formatierten Text (Ziffer 6228) in einen Custom-Karteieintrag übertragen, so kann man folgenden Weg gehen:
- Text aus GDT (auf diese GDT-Datei wird nicht durch tomedo.LINK gelauscht):
0346220Dies<ist<ein<zweizeiliger<<<Befund 1. Zeile
0416220Befund<zur<24h-Blutdruckmessung.<<<Befund 2. Zeile
0566227Anmerkungen<zu<einer<Langzeit-Blutdruckmessung.<<Kommentar
0506228Kurzzusammenfassung<24<h<Blutdruckmessung<<<formatierter Ergebnistext
0596228————————————————–<<
0596228<<<<<<<<<<<<<<Tagphase<<<<<<<<Nachtphase<<<<proz.<Abfall<<
0596228<<<<<<<<<<<<<<06:00-22:00<<<<<<22:00-06:00<<<Tag/Nacht<<<
0596228Ps[mmHg]<<<<<<143<<<<<<<<<<<<<134<<<<<<<<<<-6<%<<<<<<<
0596228Pd[mmHg]<<<<<<92<<<<<<<<<<<<<92<<<<<<<<<<<<0<%<<<<<<<
0596228HF[P/min]<<<<<<71<<<<<<<<<<<<<70<<<<<<<<<<<<-1<%<<<<<<< - Eigenes Skript schreiben, welches den obigen Text zu Testfeldern (Ziffer 8410) parsed, und eine neue GDT-Datei erzeugt (auf diese GDT-Datei lauscht dann tomedo.LINK):
…
xxx8410Tagphase_Ps
xxx8420143
xxx8421mmHg
xxx8410Tagphase_Pd
xxx842092
xxx8421mmHg
xxx8410Nachtphase_Ps
xxx8420134
xxx8421mmHg
xxx8410Nachtphase_Pd
xxx842092
xxx8421mmHg
xxx8410Abfall_Ps
xxx8420-6
xxx8421%
xxx8410Abfall_Pd
xxx84200
xxx8421%
… - Lauscheroption "Testwerte in CKE-Variablen übertragen" aktivieren und anschließender Import in einen Custom-Karteieintrag, welcher die Variablen "Tagphase_Ps", "Tagphase_Pd", etc. enthält
- Text aus GDT (auf diese GDT-Datei wird nicht durch tomedo.LINK gelauscht):
Reguläre Ausdrücke
Reguläre Ausdrücke können dazu verwendet werden Zeichenketten innerhalb einer Zeichenkette zu identifizieren, um diese weiterzuverwenden. tomedo.LINK nutzt reguläre Ausdrücke um Dateien nach ihrem Namen zu filtern oder um Zeichenketten Informationen über Patient*innen zuzuordnen. Für die Zuordnung solcher Informationen sind folgende Gruppennamen zur Verwendung hinterlegt:
- (?<V>): Die gefundene Zeichenkette wird als Vorname interpretiert. Alternative: firstName statt V.
- (?<N>): Die gefundene Zeichenkette wird als Nachname interpretiert. Alternative: lastName statt N.
- (?<P>): Die gefundene Zeichenkette wird als Patient*innen Nummer interpretiert. Alternative: patientID statt P.
- (?<Y>): Die gefundene Zeichenkette wird als Jahreszahl interpretiert. Alternative: y statt Y.
- (?<M>): Die gefundene Zeichenkette wird als Monatszahl interpretiert. Alternative: m statt M.
- (?<D>): Die gefundene Zeichenkette wird als Tageszahl interpretiert. Alternative: d statt D.
Beispiele:
- Ein GDT-Dateilauscher soll nur Dateien einlesen, deren Dateinamen mit EKG_ beginnen, bspw. EKG_test_Max_Mustermann_008.gdt.
Benötigter regulärer Ausdruck: EKG_ . - Man weiß, dass der Dateiname stets mit folgendem Muster endet: Vorname gefolgt von einem Unterstrich, gefolgt vom Nachnamen, bspw. Sono_172656_Mariä_Musterfrau.pdf.
Um die automatische Zuordnung durchführen zu können, benötigt man folgenden regulären Ausdruck: (?<V>[A-Za-zäüö]+)_(?<N>[A-Za-z]+).
Eine hilfreiche Seite um reguläre Ausdrücke zu erstellen und an Beispielen zu testen ist regex101.com.
Synchronisierte Dateiimporte
Sollten mehrere Dateilauscher (nicht vom Typ "LDT") so konfiguriert sein, dass sie die Ergebnisse in Karteieinträge des gleichen Karteieintragstyps importieren, so sind die Importe synchronisiert. Dies hat für ein Beispielszenario folgende Bedeutung:
Es kann nötig sein, dass man sowohl einen Lauscher für eine GDT-Datei als auch einen Lauscher für ein PDF verwenden muss, falls bspw. ein Gerät beides in unterschiedliche Ordner exportiert. Unter Umständen werden die Importvorgänge für die Dateien der untersuchten Person dann nahezu zeitgleich getriggert, was ohne Synchronisation sporadisch zur Erzeugung von zwei Karteieinträgen führen würde, obwohl beide Dateien in denselben Karteieintrag übernommen werden sollen.
Nutzerinteraktionen beim Import
Es kann unterschiedliche Gründe geben, weshalb eine Datei von einem Dateilauscher nicht ohne Nutzerinteraktion eingelesen werden kann.
Manuelle Patientenzuordnung
Standardmäßig wird beim einlesen einer Datei versucht, diese automatisch durch den Datei-Inhalt oder den Datei-Namen einem Patienten zuzuordnen. Sie können jedoch auch auf der Tagesliste einen Patienten anpinnen – dann werden alle erlauschten Dateien diesem Patienten zugeordnet. Sollten all diese Schritte nicht greifen, so erscheint ein Dialog zur manuellen Patientenzuordnung:
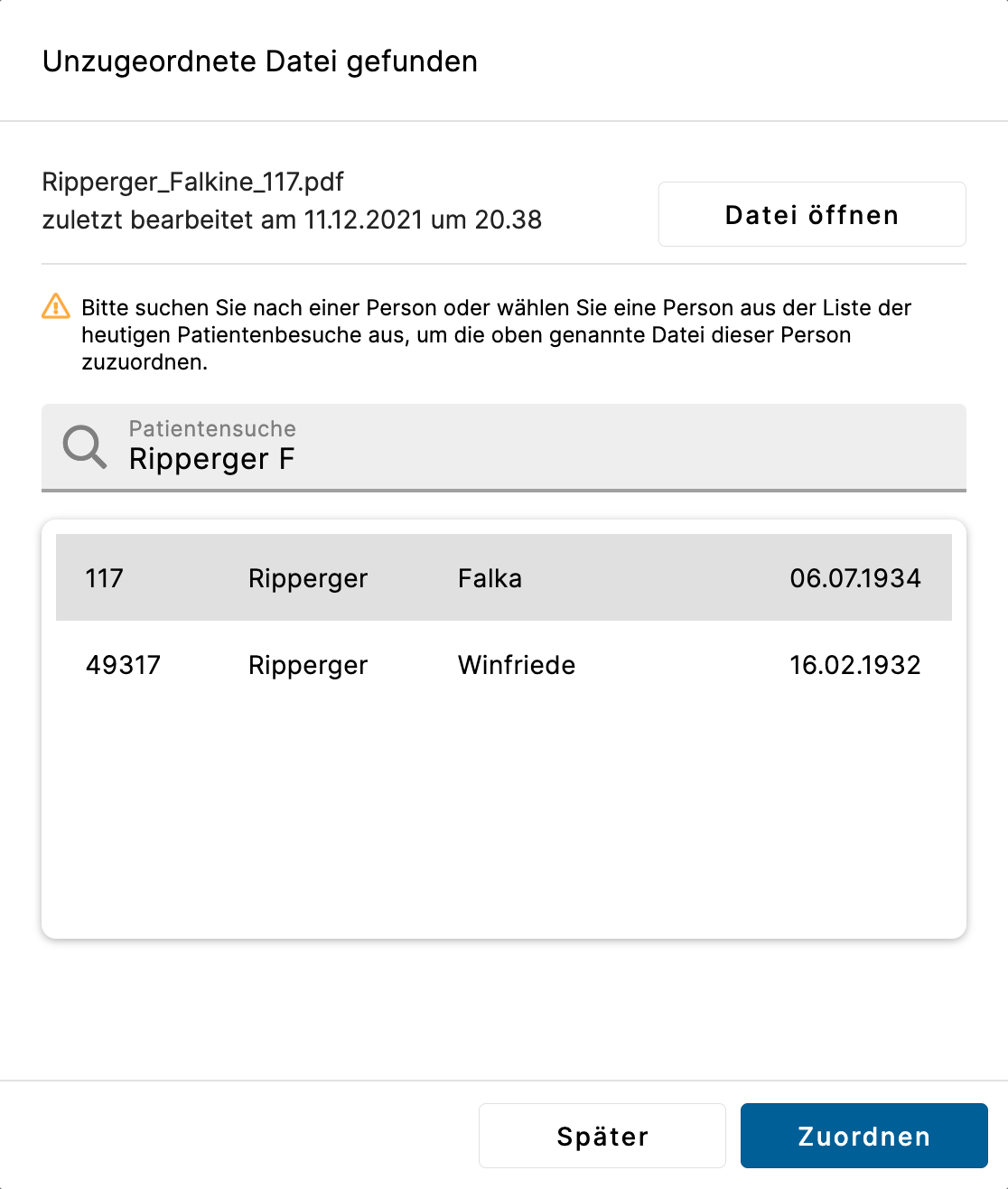
Für den Fall, dass eine Datei nicht automatisch eingelesen wird, da keine ausreichenden Informationen zur untersuchten Person aus dem Dateinamen oder der Datei extrahiert werden konnten, erscheint der Dialog zur manuellen Dateizuordnung.
Aus diesem heraus lässt sich zum einen die zu importierende Datei öffnen, um ggf. nähere Informationen zu erhalten, zum anderen soll hier eine Person zur Datei zugewiesen werden.
- Datei öffnen – Es kann sein, dass sich eine Datei nicht automatisch öffnen lässt, da für einen bestimmten Dateityp (z.b. gdt) noch kein Standardprogramm auf dem Betriebssystem hinterlegt ist. Dann können Sie Folgendes tun:
- Windows 10: Bei Öffnen einer Datei unter "öffnen mit" den Haken für "Immer diese App verwenden" setzen oder unter Start → Einstellungen → Apps → Standard-Apps festlegen. Ähnliches gilt für ältere Windows Versionen.
- Patientensuche – Standardmäßig wird eine Liste aller Personen angezeigt, die an einem Tag bereits vom Server geladen wurden, einschließlich aller Personen aus der Tagesliste.
Möchte man nach weiteren Personen in der Datenbank suchen, kann man hierzu in einem Suchfeld nach Patient*innennummer, Nachname, Vorname und Geburtsdatum suchen:- Die Suchbegriffe müssen durch Leerzeichen getrennt sein
- Die Patient*innennummer muss ohne Unterbrechung (z.b. Leerzeichen oder andere Zeichen) eingetippt werden. Es werden alle Ergebnisse angezeigt, in denen die Nummer vorkommt. Bspw. wäre die Patientin mit der Nummer 173844 ein korrektes Suchergebnis, falls man nach der Nummer 384 gesucht hätte.
- Das Geburtsdatum muss im Format dd.MM.yyyy eingegeben werden, z.b.13.09.1995
- Es müssen nicht alle Suchbegriffe verwendet werden. Schreibt man bspw. die Patient*innennummer ins Suchfeld und bekommt einige Ergebnisse und gibt dann nach einem Leerzeichen einen Nachnamen (oder einen Teil davon ein), so werden die bereits vorhandenen Suchergebnisse weiter eingegrenzt.
- Beispieleingabe: 701 Mühl 18.09.1990 (Das Ergebnis besteht aus allen Patient*innen, in deren Nummer 701 vorkommt, UND deren Vor- oder Nachname Mühl enthält UND am 18.09.1990 geboren sind)
Die manuelle Zuordnung kann entweder mit der Auswahl einer Person aus der Liste abgeschlossen werden oder aber, sofern eine Zuordnung zu diesem Zeitpunkt nicht möglich ist, über Später verschoben werden. In letzterem Fall erscheint eine neue Nachricht unter Meldungen, aus welcher der Dialog zur Patientenzuordnung sich erneut öffnen lässt, siehe Benachrichtigungen.
Bereits eingelesene Datei
Für jeden Dateilauscher wird eine Liste bereits eingelesener Dateien geführt, um ungewollte Dopplungen zu vermeiden. Diese Liste wird bei einer Deaktivierung des Lauschers oder einem Neustart des Programms zurückgesetzt. Wird eine bereits eingelesene Datei erneut in das belauschte Verzeichnis gelegt, kann der Nutzer über einen Dialog entscheiden, wie mit der Datei verfahren werden soll.
- Archivieren: Die Datei wird in den Archivordner verschoben und nicht erneut importiert
- Löschen: Die Datei wird aus dem Verzeichnis gelöscht und nicht erneut importiert
- Fortfahren: Die Datei wird erneut importiert
Handelt es sich um eine Datei, bei der der Import fehlgeschlagen ist, wird automatisch versucht sie erneut einzulesen.
Leere Datei
Um auf eventuelle Probleme im System aufmerksam zu machen, erscheint ein Dialog wenn ein Datei-Lauscher eine leere Datei erkannt hat. Dazu zählen Dateien deren Größe nur 0 Byte beträgt, sowie GDT-Dateien in denen alle GDT-Feld Kenn-Nummern gefehlt haben bzw. keinen Wert haben. Sie haben drei Auswahlmöglichkeiten:
- Archivieren: Die Datei wird ohne Patientenzuweisung in den Archivordner verschoben
- Löschen: Die Datei wird aus dem Verzeichnis gelöscht und nicht importiert
- Fortfahren: Es wird mit dem Import fortgefahren